Decision tree learning is a supervised machine learning method used in statistics and data mining. It involves creating a predictive model in the form of a classification or regression tree based on a set of observations. Classification trees are used when the target variable has discrete values, representing class labels, while regression trees are employed for continuous values. Decision trees are popular for their simplicity and intelligibility. They visually represent decisions and decision-making processes, making them useful in decision analysis. In data mining, decision trees describe data, and the resulting classification tree can be used for decision-making.
Decision tree learning is widely used in data mining is aiming to create a predictive model for a target variable based on multiple input variables. In this context, a decision tree is a straightforward representation used for classifying examples. Assuming finite discrete domains for input features and a single target feature called "classification," the decision tree comprises nodes labeled with input features and branches labeled with possible values of the target feature.
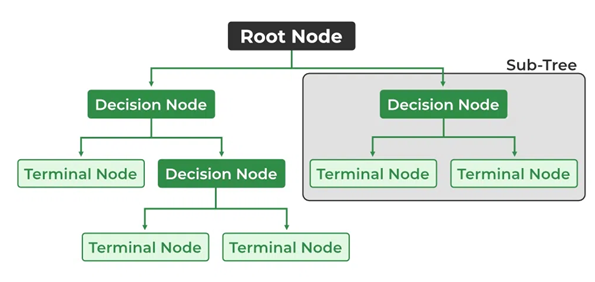
The tree-building process involves recursively splitting the source set into subsets based on classification features, creating internal nodes and decision paths. This top-down induction of decision trees is a greedy algorithm, where each node is split to maximize predictive value. The recursion stops when subsets have uniform values for the target variable, or further splitting adds minimal predictive value.
The data consists of records in the form \((\mathbf{x}, Y) = (x_1, x_2, x_3, ..., x_k, \, Y)\) , where \(Y\) is the target variable, and \(\mathbf{x}\) is the feature vector used for the task.
Notable decision tree algorithms include ID3 (Iterative Dichotomiser 3), C4.5 (a successor of ID3), and CART (Classification And Regression Tree). These algorithms were developed independently but follow a similar approach for learning decision trees from training tuples.
Additionally, concepts from fuzzy set theory have been proposed for a special version of a decision tree known as Fuzzy Decision Tree (FDT), where an input vector is associated with multiple classes, each having a different confidence value. Boosted ensembles of FDTs have been suggested for improved performance.
Let’s take a brief look at two algorithms in the following.
Let’s take a brief look at two algorithms in the following.
The ID3 algorithm begins with the original set \(S\) as the root node. On each iteration of the algorithm, it iterates through every unused attribute of the set (\S\) and calculates the entropy \(H(S)\) or the information gain \(IG(S)\) of that attribute. It then selects the attribute which has the smallest entropy (or largest information gain) value. The set \(S\) is then split or partitioned by the selected attribute to produce subsets of the data.
in summary:class sklearn.tree.DecisionTreeClassifier(*, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0)import backtrader as bt
from sklearn.tree import DecisionTreeClassifier
import numpy as np
import pandas as pd
import yfinance as yf
import matplotlib.pyplot as plt
class MLStrategy(bt.Strategy):
params = (
("lookback_period", 30),
("decision_tree_model", DecisionTreeClassifier())
)
def __init__(self):
self.data_close = self.datas[0].close
self.data_open = self.datas[0].open
self.decision_tree_model = self.params.decision_tree_model
self.lookback_period = self.params.lookback_period
self.rsi = bt.indicators.RelativeStrengthIndex(self.data_close, period=14)
self.volume = self.datas[0].volume
self.order = None
def next(self):
if len(self) > self.lookback_period:
# Convert array.array to NumPy arrays for subtraction
close_prices = np.array(self.data_close.get(size=self.lookback_period))
open_prices = np.array(self.data_open.get(size=self.lookback_period))
price_diff = close_prices - open_prices
rsi_values = np.array(self.rsi.get(size=self.lookback_period))
volume_values = np.array(self.volume.get(size=self.lookback_period))
# Feature generation
features = np.column_stack((price_diff, rsi_values, volume_values))
# Decision tree input
X = features.reshape(-1, 3)
# price directions
y = np.sign(np.diff(self.data_close.get(size=self.lookback_period + 1)))
# Train the decision tree model
self.decision_tree_model.fit(X[:-1], y[1:])
# Predict using decision tree
prediction = self.decision_tree_model.predict(X[-1:])
# Check if there is no open position
if not self.position:
cash = self.broker.get_cash()
asset_price = self.data.close[0]
position_size = cash / asset_price * 0.99
# Make trading decision based on prediction
if prediction[-1] == 1:
self.buy(size=position_size)
else:
if prediction[-1] == -1:
self.close()
def notify_order(self, order):
if order.status in [order.Submitted, order.Accepted]:
return
# Check if an order has been completed
if order.status == order.Completed:
if order.isbuy():
self.log(f"Buy executed: {order.executed.price:.2f}")
elif order.issell():
self.log(f"Sell executed: {order.executed.price:.2f}")
# Reset order
self.order = None
def log(self, txt, dt=None):
dt = dt or self.datas[0].datetime.date(0)
print(f"{dt.isoformat()}, {txt}")
if __name__ == '__main__':
# Create a Cerebro engine
cerebro = bt.Cerebro()
# Add data
data = bt.feeds.PandasData(dataname=yf.download('BTC-USD',
period='3mo',
))
cerebro.adddata(data)
# Add the strategy
cerebro.addstrategy(MLStrategy)
# Set the initial cash amount
cerebro.broker.setcash(100.)
cerebro.broker.setcommission(.001)
print(' Brokerage account: $%.2f' % cerebro.broker.getvalue())
cerebro.run()
print(' Brokerage account: $%.2f' % cerebro.broker.getvalue())
# Plot the strategy
plt.rcParams["figure.figsize"] = (10, 6)
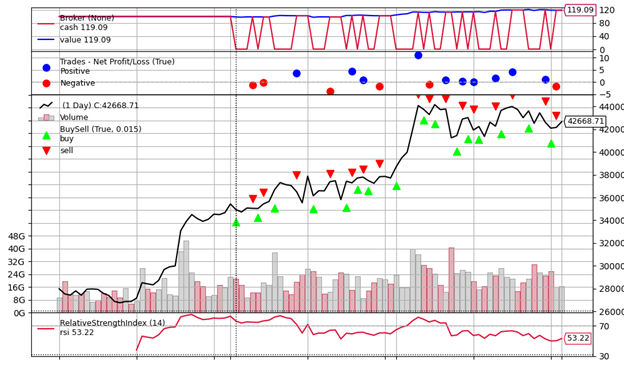
cerebro.plot()
Have questions? I will be happy to help!
You can ask me anything. Just maybe not relationship advice.
I might not be very good at that. 😁